A common pitfall with microservice design is to have direct communication between several services. This leads to multiple transactions across multiple services in order to complete a single top-level transaction. In essence, a monolith was created which evolved into a distributed monolith. It’s the worst part of both paradigms.
For the purposes of this article, a transaction represents a request that triggers complex interactions between microservices, and to provide clarity some diagrams have been simplified and may not include certain implementation details.
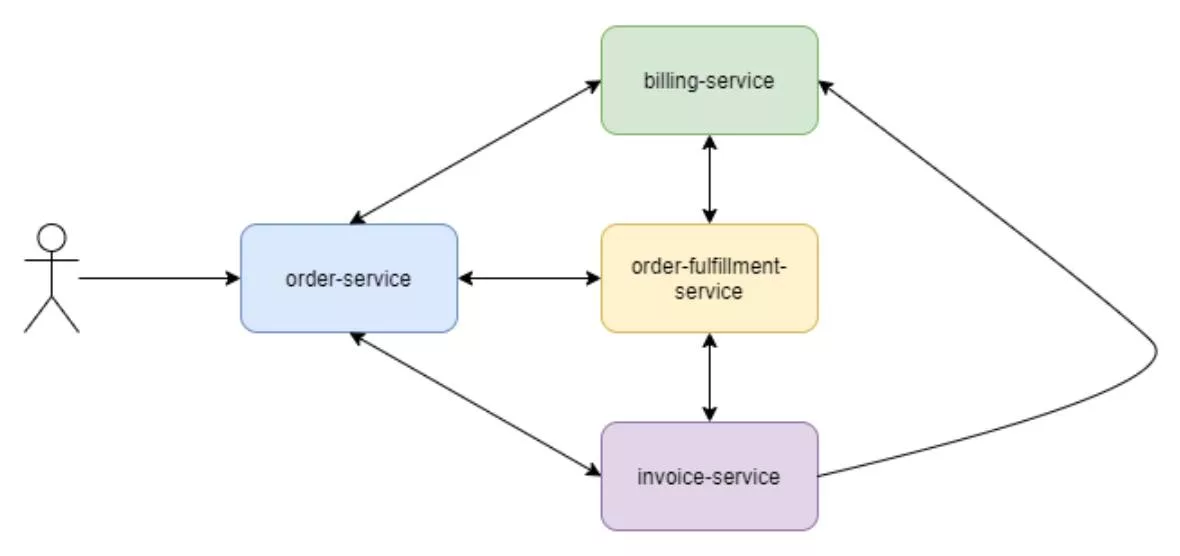
A common strategy for resolving this issue is to utilize a message bus to decouple the services. The advantages of this approach include:
- Asynchronous downstream processing when needed or wherever possible.
- Uninterrupted transaction processing in the event of a service outage.
- Automatic transaction re-queuing and reprocessing following an outage or after a bug fix has been pushed to production.
- New processing steps can be added by adding another consumer to the message bus.
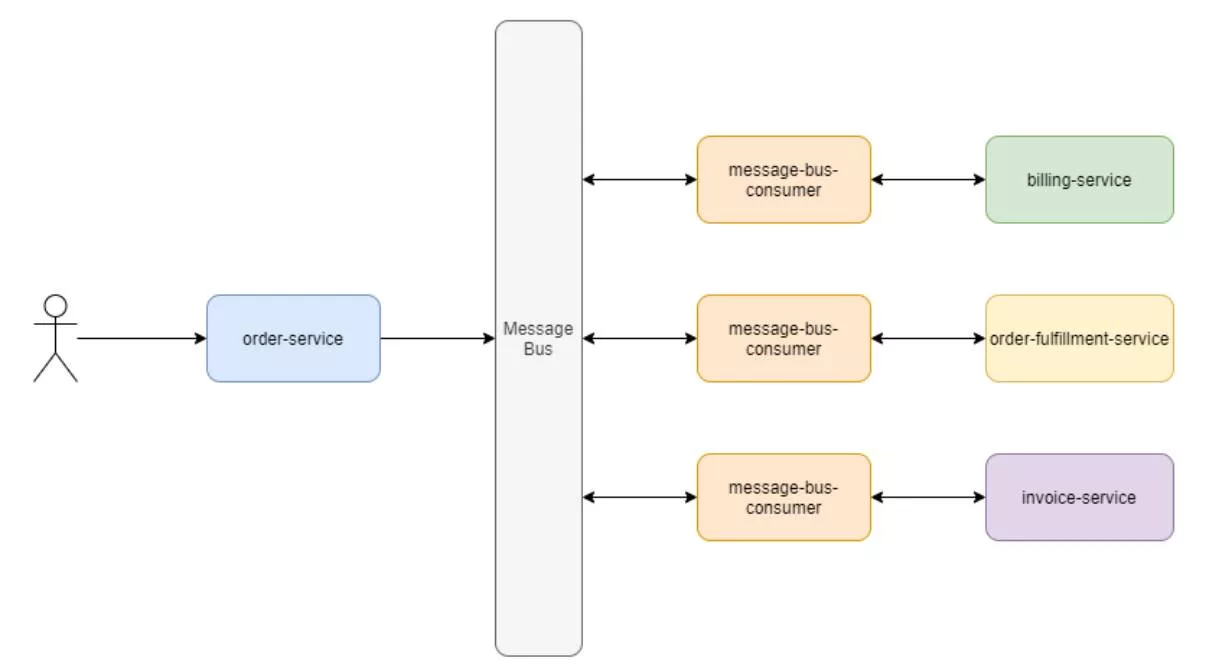
There are a variety of technologies that could be used in the implementation above, such as SQS, SNS, RabbitMQ, Kafka, Redis, ActiveMQ, etc. The consumer implementation will be dependent on the broker used, but it will contain common elements:
- Retry logic for requests to the services.
- The ability to acknowledge, or unacknowledge (unack in system), the receipt of a message and its processing success or failure.
- Saturating the data in the bus for any downstream dependencies, i.e. IDs or instances of newly created transactions, transaction metadata, etc.
- Producing new messages to trigger downstream processing.
- Auto-scaling capabilities based on the queue or topic size in the message bus. Just like the auto-scaling capabilities of the services themselves, the consumers and producers can scale.
Engineers often use finite state machines (FSM) to represent state, backend processes, etc. While several notation standards exist that can be used to represent finite state machines, we often use basic flow charts to represent FSMs. Business Process Model Notation (BPMN) offers a standard that can be understood by both engineering teams and business stakeholders for creating FSMs. The beauty of BPMN is that both the engineers and the business stakeholders speak the same language when discussing a business process, which eliminates the kind of “translation” errors we see when modeling the domain (Business Process Model and Notation (BPMN), Version 2.0).
For example, the BPMN diagram below represents the process for creating an order; the steps are clear and can be easily understood by both the business stakeholders and engineers:

These diagrams are not limited to communication. Through the use of a BPMN engine, the diagram above can be published to an engine that will invoke the steps. This allows us to utilize the same diagram to orchestrate the work that we used to model the process with the business.
There are several ways that a BPMN engine can be integrated into a system to perform microservice orchestration. However, it’s important to note that depending on the engine used, not all engines offer the same level of capability and available features will vary. For example, Activiti focuses on providing core engine capabilities and rely on external infrastructure to perform tasks such as I/O. Other engines are really offered as platforms, such as Camunda which contains a core BPMN and rules engine but it ships with additional infrastructure and capabilities.
Therefore, the examples below will vary depending on which engine is used. [NB. Camunda is a fork of Activiti, so there is an overlap between those two particular engines.] In these examples, the BPMN Engine Worker could be a thread inside of the BPMN engine itself, or it could be an external component. For best practice, utilizing the external task pattern, where the work for the task is performed by a component external to the BPMN engine, is preferable to using script tasks for I/O or complex processing logic.
NB. All references to a “gateway” shown in the diagrams below denote some sort of interface (e.g., REST API, API GW, gRPC API, microservice, etc.) that sits in front of the components.
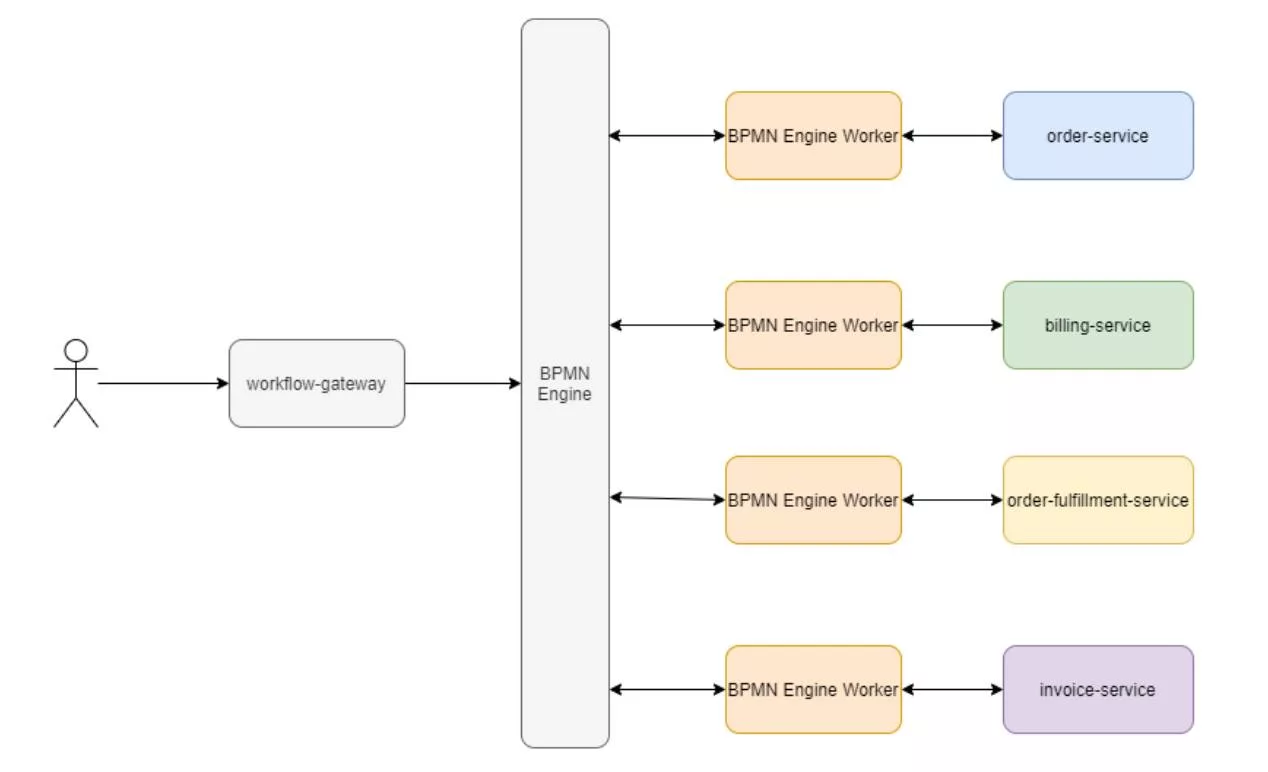
In the most basic example, a gateway-like service sits in front of the BPMN engine and the BPMN essentially serves as the message bus. This is possible with Camunda which has an internal message bus and allows for subscriptions to topics that correspond to tasks. The ‘workflow gateway’ depicted is some sort of logical component that communicates with the engine. Camunda ships with a REST API, so it has the capability built-in and the two logical components are the same deployed component.
Similar to the pattern where the engine is also used as a message bus, this pattern separates the message bus from the engine itself. In this case, the engine’s workflows are triggered by a message bus consumer responsible for invoking workflows:
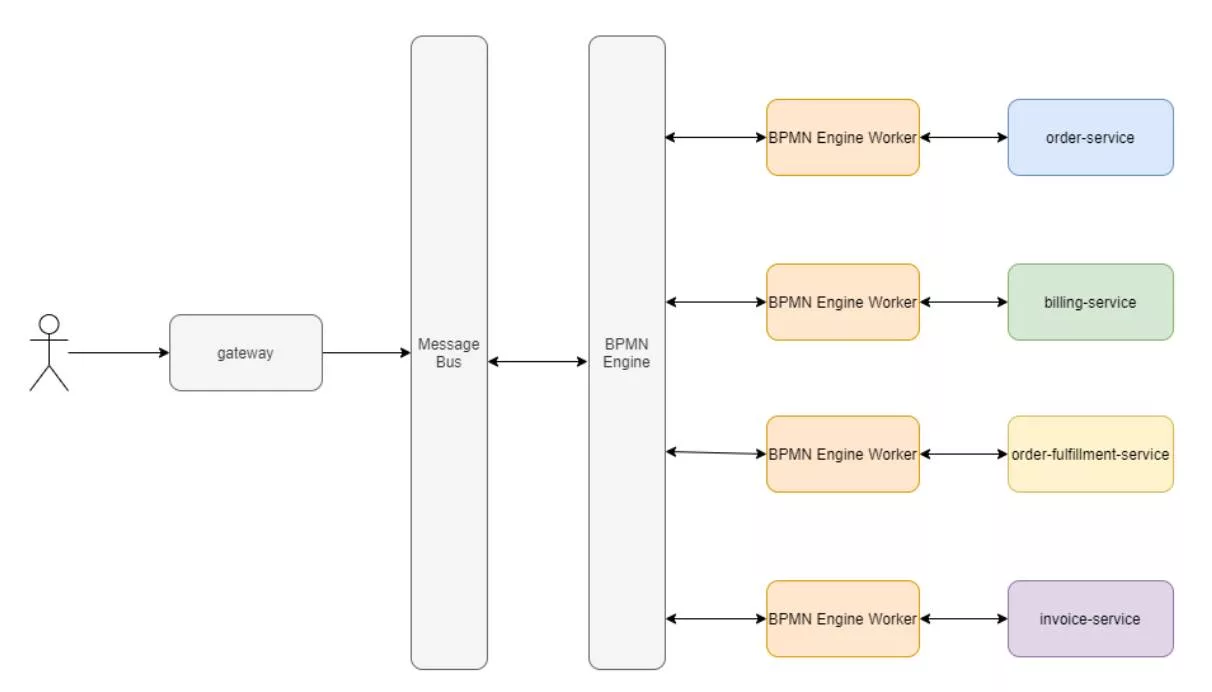
This pattern can also be inverted, where the engine communicates with the message bus and the message bus consumers operate against the microservices:
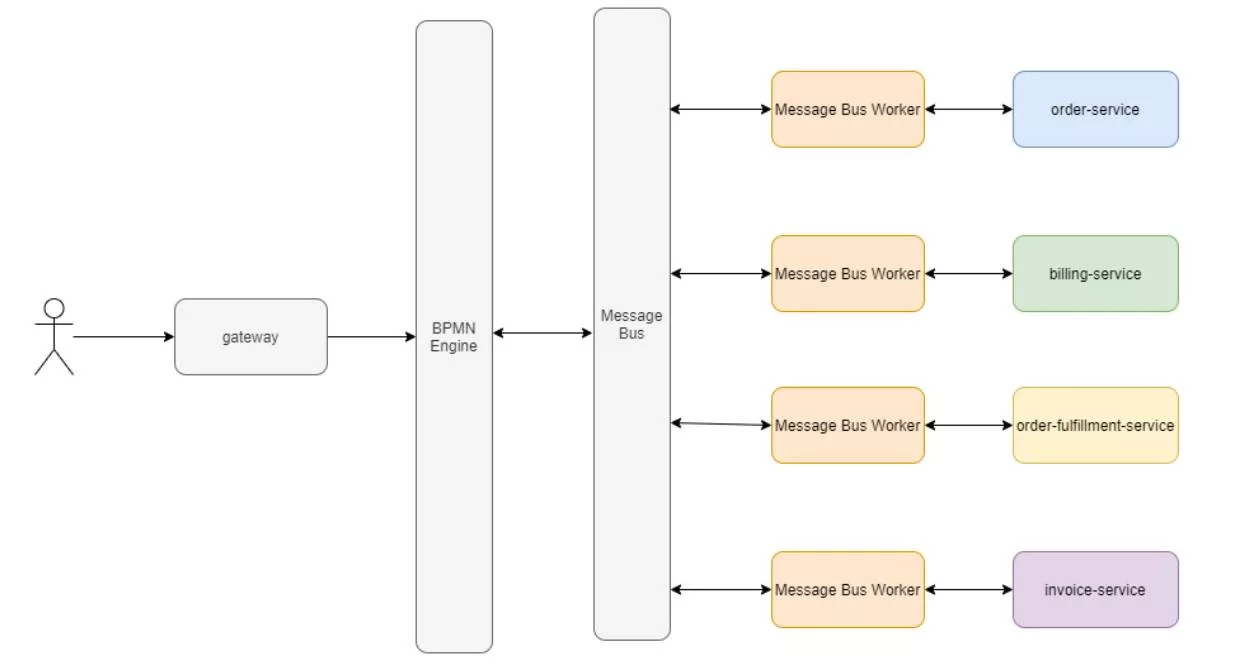
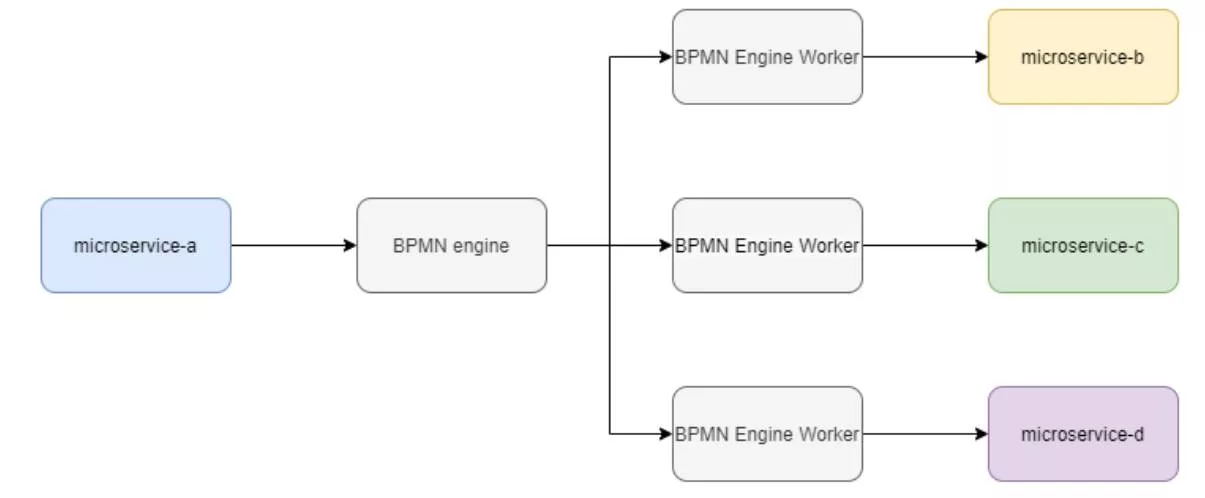
In this scenario, each microservice ships with access to an engine/workflow instance that is specific to the microservice. This could be performed by embedding the BPMN engine into the service itself and shipping the engine as part of the logical microservice that runs in a separate process (think two containers for the service instead of one). Alternatively, using dedicated workflows in the main engine instance to individual microservices, as in this example Camunda implementation:
Since we are actively using Camunda, we will use examples from Camunda to keep any code examples or implementation details relevant to the team. The source code for the Camunda NodeJS Client can be found here.
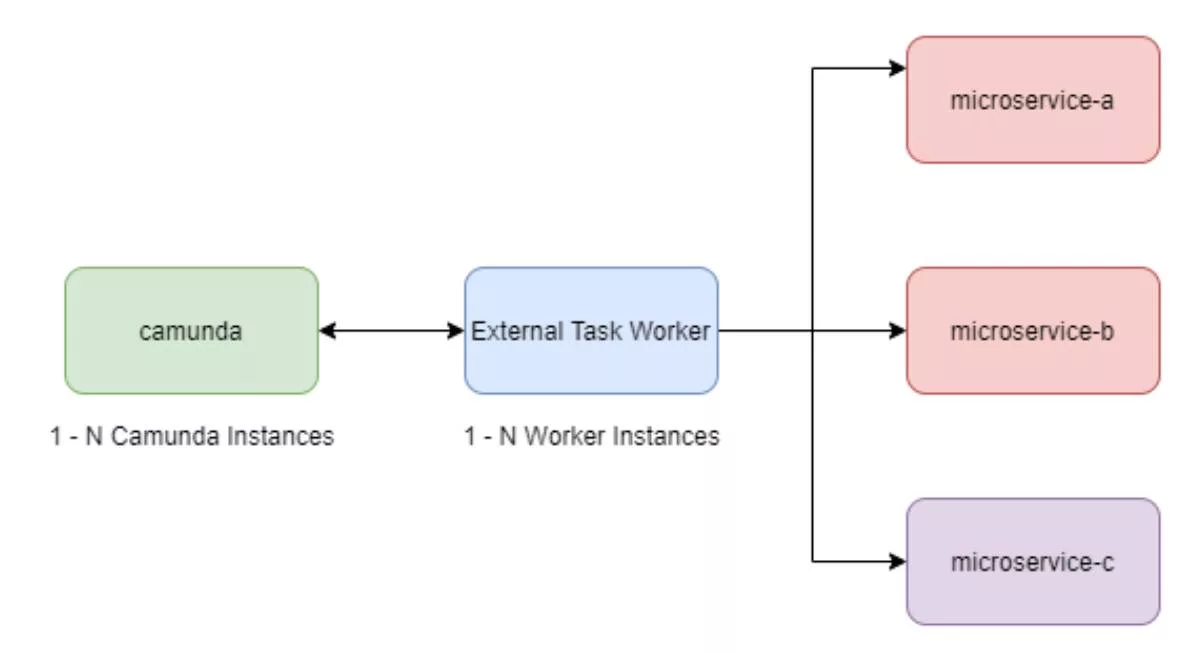
The key highlights of this pattern are:
- Camunda is horizontally scalable
- The external task worker(s) is horizontally scalable
- The microservices are horizontally scalable
With appropriate auto-scaling configurations, the system will be able to handle back pressure effectively and scale up and down as needed. If needed, the various patterns below can be used in combination.
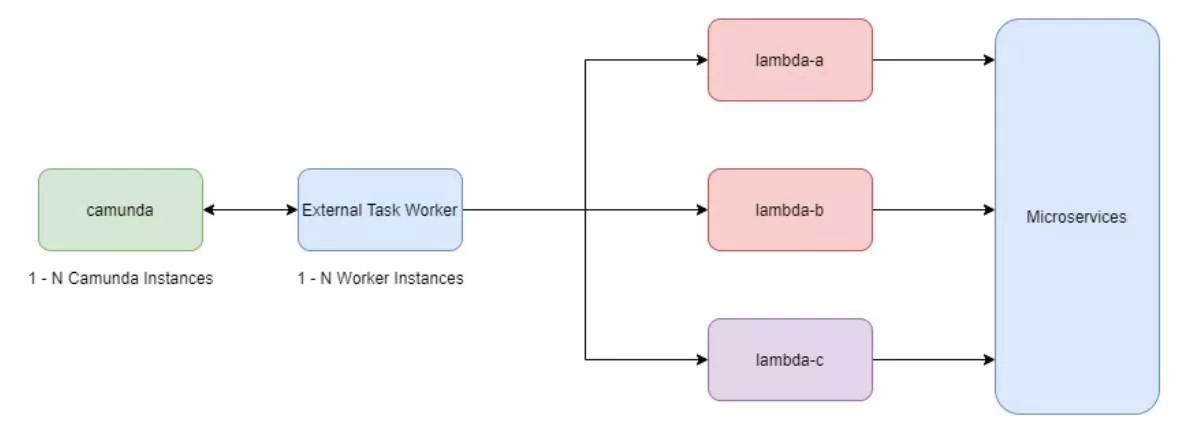
This pattern works similarly to the Basic Worker Pattern in that the External Task Worker is responsible for mapping topics to Lambdas and marshaling data between the Lambda invocations and process instances. This pattern adds an additional layer of abstraction and scalability, however, it does add more complexity. It can be useful in scenarios where Lambdas are interacting with third-party systems or AWS services since the Lambdas can be reused elsewhere in the stack or abstract away any implementation details of interacting with third-party services.

