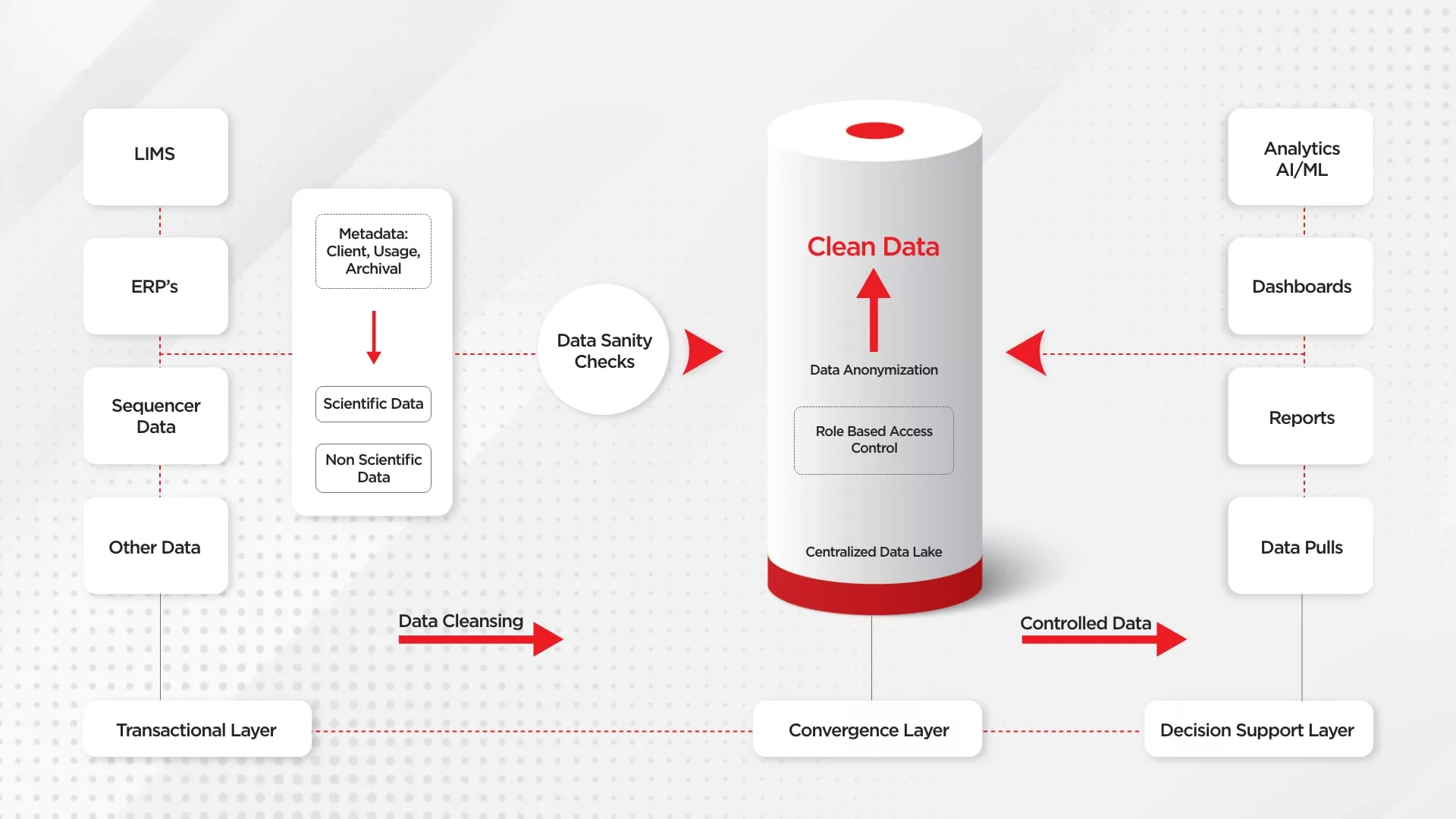
Bio-pharmaceutical companies and contract research organizations (CROs) are constantly seeking ways to improve and accelerate the drug discovery and development process. One way that has shown significant potential is the use of centralized data lakes and data analytics using cloud technologies and medical cloud services.
A data lake is a centralized repository that enables data aggregation and allows you to store all your structured and unstructured data at any scale. It is a flexible and cost-effective way to store large amounts of data and makes it easy to process and analyze this data using various tools and technologies.
Learn more about SourceFuse Data Analytics
In the context of drug discovery and clinical trials, data lakes can be used to store and analyze a wide range of data types, including analytical chemistry, assay biology, drug metabolism and pharmacokinetics (DMPK), NGS and genomics, clinical trial data, electronic health record (EHR) data, LIMS, and more. By aggregating all of this data in a centralized location, a data lake enables project leaders, scientists and researchers to gain a comprehensive view of the project and research pipeline.
Data analytics tools can then be used to mine this data for insights and trends that can inform decision making and accelerate the drug discovery process. For example, machine learning algorithms can be used to identify patterns in genomics data that may point to potential drug targets. Similarly, natural language processing (NLP) can be used to extract information from EHR and clinical trial data, providing valuable insights into patient outcomes and side effects.
Some examples of such dashboards are:
- Cycle time for each stage of research
- Performance of each stage
- Quality – % compounds rejected
- Number of requests, ratio of review cycles, experiments, Number of compounds created, Number of sequence created, % experiments cancelled
- Number & % of projects delayed
- % of projects waiting to start
- % of projects waiting on procurements/purchases & time impact
- Lab / Equipment / Scientist utilization and forecasts
- Project pipeline vs utilization trends
Additionally, data lakes and analytics can help improve the accuracy and reliability of clinical trial data by providing a centralized location for data storage and management. This can help ensure that data is accurate and consistent, which is crucial for the success of clinical trials.