Let’s ask the same “how many moons” question with the ChatGPT.

As you can see, it also mentions this information is only valid as per its last update. If we need our model to answer this question correctly, we would need to retrain our LLM, which is not always feasible. In addition, it would be very challenging and uneconomical to keep your LLMs ‘in the swim’.
That’s where Retriever Augmented Generation (RAG) comes in, a strategy that helps address both LLM hallucinations and out-of-date training data. Pairing the LLMs with this architecture boosts its capabilities despite spending time and money on additional training.
The way large language works is that the user asks the question, also known as a prompt, about moons, and an LLM will confidently answer “Jupiter” since it knows only that from the parameters during the training. The LLM would be quite confident while doing this response generation, although it would most likely be wrong.
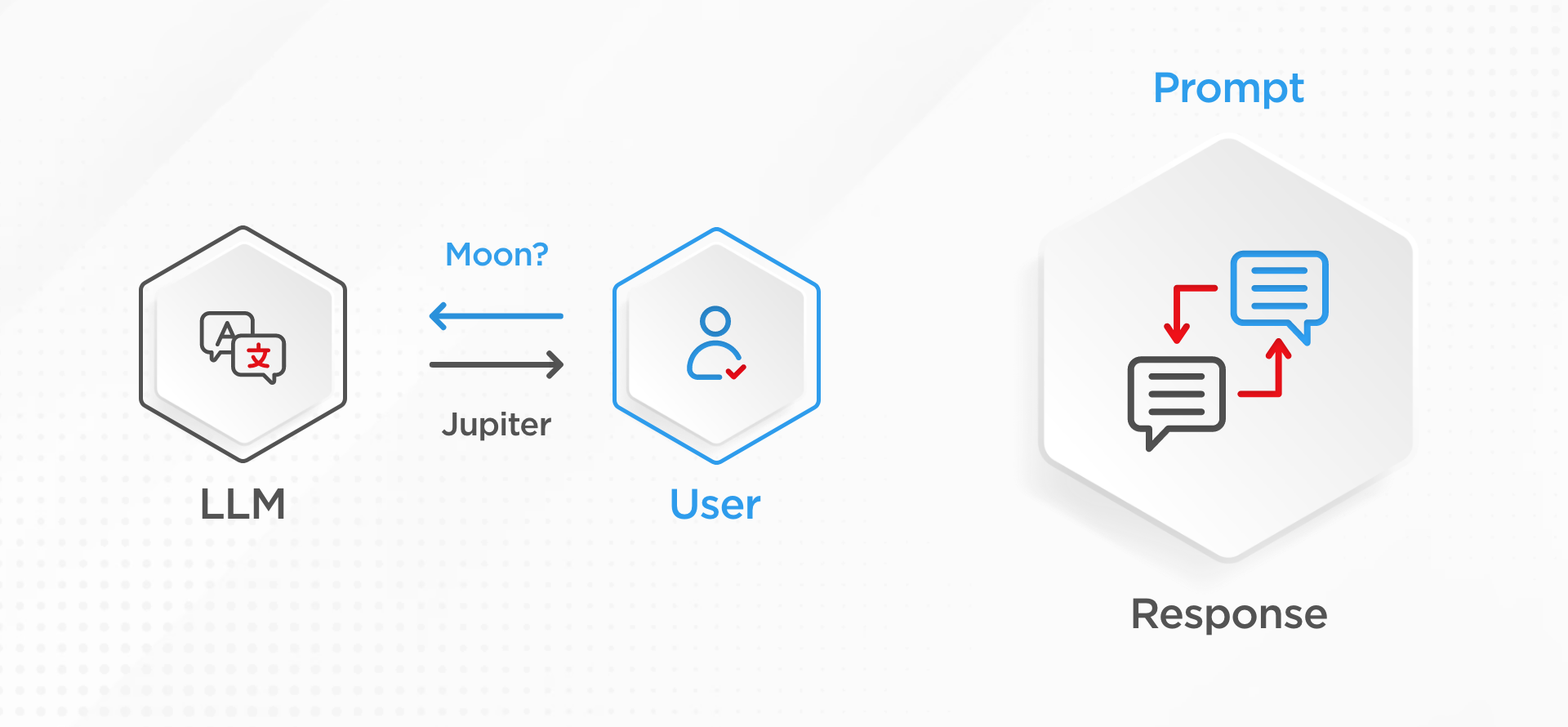
However, when you add retrieval augmentation with this generation process, instead of relying on just what LLM knows, we would add content store data. This content store data could be anything: a collection of documents, internal or external databases, or even the open internet. By doing this, LLM now has an instruction set provided along with the prompt that says:
- First, go and look into this content store for the related information that is contextually relevant and combine that with the user’s question.
- And only then generate the response along with the evidence of why the response was what it was.

